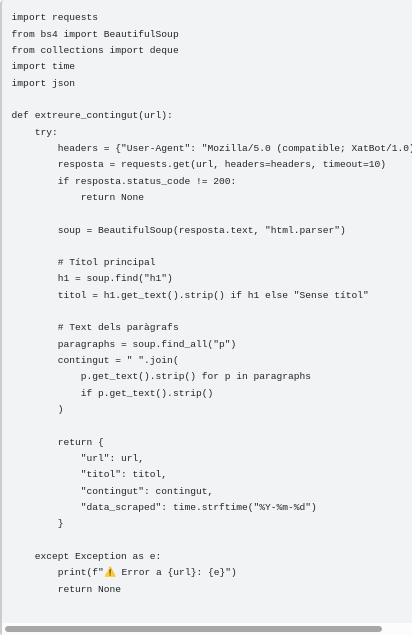
Extracció de dades web amb BeautifulSoup S’ha desenvolupat un script de web scraping que automatitza la recol·lecció de contingut rellevant. El programa filtra els elements secundaris, com ara menús i capçaleres, per centrar-se exclusivament en l’obtenció de la jerarquia de títols ($h1$, $h2$, $h3$) i el cos dels paràgrafs ($p$).
Pas 1 – Configuració dels primers passos del scraper
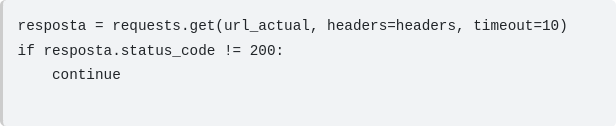
2 –Automatització del rastreig i persistència de dades El sistema realitza un recorregut exhaustiu per múltiples URLs, implementant un control d’unicitat per evitar duplicats. Finalment, l’estructura de dades resultant s’exporta i s’emmagatzema en un fitxer amb format JSON per a la seva posterior consulta.
Pas 3 – Afegir la llista de pàgines a visitar
Pas 4 – Executar el programa de copia
Gestió de la freqüència de peticions Per tal de garantir un comportament ètic i evitar la saturació del servidor de destinació, s’ha implementat un interval de latència de 0,3 segons entre cada accés consecutiu.
S’ha implementat un sistema de control d’errors que detecta qualsevol incidència en accedir a una URL. En cas de fallada, el programa registra una notificació d’error i omet la pàgina afectada per garantir que el procés de recollida de dades no s’interrompi.
S’ha definit un màxim de 10 segons per a la resposta del servidor. Si una pàgina supera aquest temps, el programa avorta la petició automàticament i reprèn el procés amb el següent objectiu per evitar retards innecessaris.
Pas 5 – Afegir el retard i el temps màxim
Pas 6 – Missatges quan hi ha errors
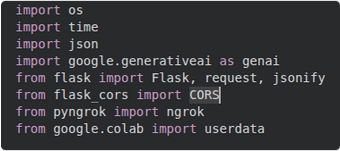
4 – Treball amb IA per corregir i millorar el codi
L’assistent d’IA ha ajudat a escriure el codi inicial i a corregir el que anava malament, especialment per connectar el programa amb el xatbot i arreglar errors de connexió.
Permetre peticions del navegador: s’ha afegit CORS perquè el web i el servidor puguin parlar bé.
Port ocupat: s’acaben connexions antigues abans d’obrir‑n’hi una de nova.
5 – Gestió del repositori i documentació a GitHub
El codi font s’allotja a GitHub, on s’ha estructurat la documentació mitjançant dos fitxers fonamentals que descriuen l’arquitectura del projecte.
5.1 – Arxiu README Aquest fitxer proporciona una visió general del projecte, detallant-ne les funcionalitats principals, els requeriments tècnics i les instruccions detallades per a la seva configuració i posada en marxa.
5.2 – Arxiu CHANGELOG Aquest fitxer recull l’historial detallat de les modificacions realitzades en el projecte. Permet fer un seguiment cronològic de les noves funcionalitats, les correccions d’errors i les millores implementades en cada versió del programari.
Asistent d'en Miquel
En línia • Intel·ligència Artificial
Hola! Soc l'assistent virtual d'en Miquel. En què et puc ajudar avui sobre el seu portafolis?